We find that organisations are often unable to exploit to the maximum the large amount of data they collect about their activities due to:
- The structure of the data
- Errors and anomalies in the data
- Limited understanding of the tools at their disposal
- Limited understanding of more advanced data analysis tools, such as the python programming language
We clean, restructure, merge, analyse, and present data in different ways, to help clients extract greater insights from their existing data. We also make recommendations on organisational data collection, analysis, and presentation tools and processes.
Data analysis case studies
European Parliament
In 2020 we analysed European Commission and European Parliament data in the context of a European Parliament study on ‘Pilot Projects And Preparatory Actions (PP/PA) in the EU Budget 2014-2019’ undertaken by Blomeyer & Sanz.
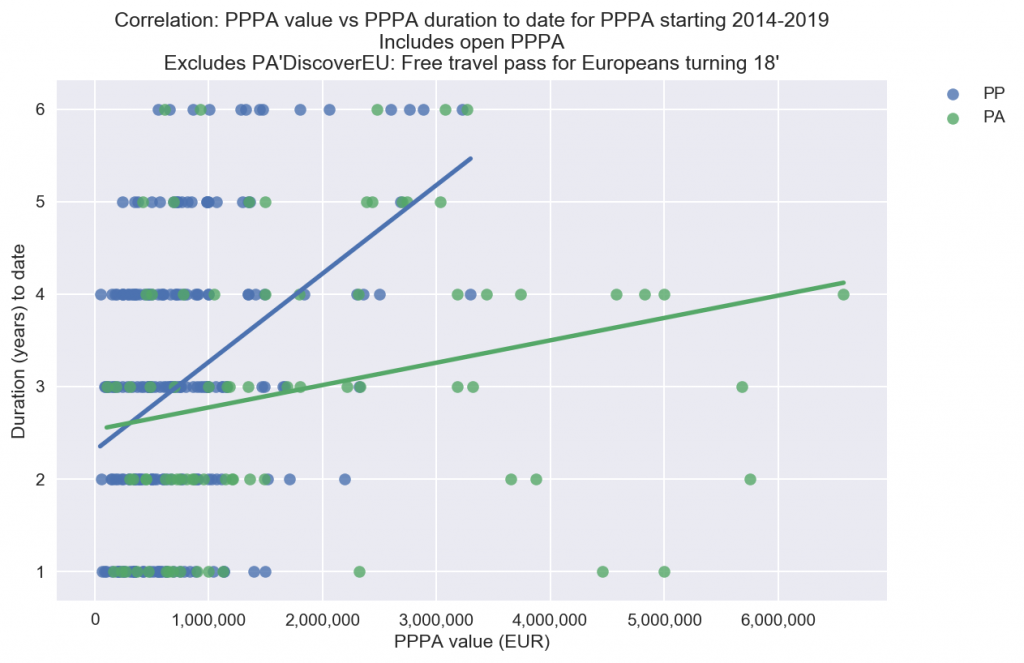
Analysis from the study showing that the values of Preparatory Actions tend to increase more slowly than Pilot Projects as duration increases
We were provided with two sets of data. One included complex financial information for 588 PPPA. The other listed the results of European Commission pre-assessments of 1,887 PPPA proposals. Both sources of information are generated for specific reporting purposes and had to be restructured in order to undertake analysis for the study.
The two data sets were then merged in order to analyse the extent to which proposals in each of four different possible pre-assessment categories were subsequently funded.
We made a number of recommendations on the structure, content, and presentation of the data for different purposes.
Intergovernmental organisation
This example uses randomly generated data to illustrate another case.
We were provided with a large spreadsheet where rows represented projects and columns represented donors. The cells contained textual data consisting of payment amounts and dates. Many of the cells included multiple entries. We parsed, cleaned, and restructured the data and introduced classifications. This enabled us to undertake many different types of analysis, examples of which are provided below.





